為什麼要認識瀏覽器勒?因為我們在進行網路爬蟲時,第一個步驟就是需要使用瀏覽器,來瀏覽我們想要爬取的網頁,並且在網頁中選取有用的資料,再依照平常瀏覽網頁的過程,例如說進到網頁時會先逐筆的看完所有商品,再跳下一頁繼續觀看,這個過程就等於是網路爬蟲代替我們爬取資料。
使用HTTP通訊協定,當你輸入網址(URL)時,實際上是向Web伺服器發送HTTP Request(請求),這種請求通常是一個GET(取得資料)請求,然後伺服器會回應您的請求,並返回HTTP Response(回應)。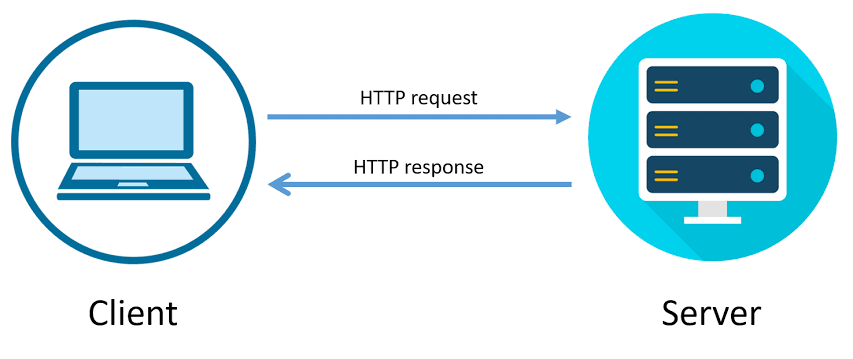
當瀏覽器接收到伺服器回應的HTML網頁後,就會將網頁內容剖析,並且建立樹狀結構(DOM),而樹狀結構是一種階層結構的標籤,每個標籤都是成對的。使用格式方法:<標籤名稱>…</標籤名稱>,結尾記得要加上/符號。
<html>
<head>
<title>…</title>
<head>
<body>
<div>
<h1>…</h1>
<p>…</p>
</div>
</body>
</html>
最後,瀏覽器會根據伺服器返回的HTML和CSS內容,來呈現我們在瀏覽器中看到的網頁畫面。

